Journals > > Topics > Instrumentation, Measurement and Metrology
Instrumentation, Measurement and Metrology|590 Article(s)
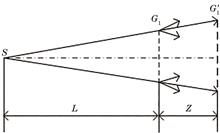
Collimation Technique for Infrared Beam Based on Moire Fringe
Shangchen Cai, Qiluan Chen, Shu Zhang, and Zuojun Tan
A method of infrared beam collimation adjustment based on the Moire fringe is proposed based on the Talbot image of the grating and its relationship to beam collimation under spherical wave illumination. When the grating is moving, the change in the Moire fringe direction is observed and measured by an infrared array charge-coupled device (CCD) to adjust the beam collimation. As a result, fast and convenient collimation of the infrared beam is realized. The results show that, when the grating moves, because the distance is the same, the optical path changes of 0-order and ±1-order light waves differ. The fringe shows periodic vertical axis movement and periodic contrast change, but the fringe direction remains unchanged. The fringe movement and contrast change do not affect the collimation accuracy. This method overcomes the difficulty of an invisible infrared beam and achieves simpler, faster, and more convenient collimation correction than the traditional collimation method. A method of infrared beam collimation adjustment based on the Moire fringe is proposed based on the Talbot image of the grating and its relationship to beam collimation under spherical wave illumination. When the grating is moving, the change in the Moire fringe direction is observed and measured by an infrared array charge-coupled device (CCD) to adjust the beam collimation. As a result, fast and convenient collimation of the infrared beam is realized. The results show that, when the grating moves, because the distance is the same, the optical path changes of 0-order and ±1-order light waves differ. The fringe shows periodic vertical axis movement and periodic contrast change, but the fringe direction remains unchanged. The fringe movement and contrast change do not affect the collimation accuracy. This method overcomes the difficulty of an invisible infrared beam and achieves simpler, faster, and more convenient collimation correction than the traditional collimation method.
Laser & Optoelectronics Progress
- Publication Date: May. 10, 2024
- Vol. 61, Issue 9, 0912001 (2024)

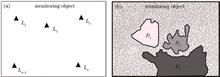
Multiscale Deformation Monitoring Based on Terrestrial 3D Laser Scanning Technology
Xiantao Guo, Lijun Yang, and Ya Kang
Regarding the deficiency of traditional deformation monitoring in effectively detailing deformation of local unique monitoring objects due to the overall deformation model, this paper proposes a three-layer mixed deformation model, i.e., block, region, and overall deformation, based on terrestrial 3D laser scanning technology. A block-based deformation calculation method is also designed. This method mainly includes object segmentation, deformation estimation, and deformation fusion, and can automatically extract deformation information of different scales without prior monitoring information. Simulation results show that under this method, the mean angle change estimation error of RANSAC algorithm plane fitting regression is 1.21″, and the estimation reliability increases with an increase in block size within a certain range. The results of the landslide experiment show that the minimum value method has less displacement estimation noise, and a 0.2 m block size segmentation can provide further deformation estimation details. The proposed method is particularly suitable for monitoring fields with nonuniform deformation characteristics, and has certain theoretical and practical significance for promoting the transformation of disaster monitoring from"point monitoring"to"surface monitoring"for landslides and other disasters that are difficult for personnel to reach. Regarding the deficiency of traditional deformation monitoring in effectively detailing deformation of local unique monitoring objects due to the overall deformation model, this paper proposes a three-layer mixed deformation model, i.e., block, region, and overall deformation, based on terrestrial 3D laser scanning technology. A block-based deformation calculation method is also designed. This method mainly includes object segmentation, deformation estimation, and deformation fusion, and can automatically extract deformation information of different scales without prior monitoring information. Simulation results show that under this method, the mean angle change estimation error of RANSAC algorithm plane fitting regression is 1.21″, and the estimation reliability increases with an increase in block size within a certain range. The results of the landslide experiment show that the minimum value method has less displacement estimation noise, and a 0.2 m block size segmentation can provide further deformation estimation details. The proposed method is particularly suitable for monitoring fields with nonuniform deformation characteristics, and has certain theoretical and practical significance for promoting the transformation of disaster monitoring from"point monitoring"to"surface monitoring"for landslides and other disasters that are difficult for personnel to reach.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812009 (2024)
Defect Detection of Photovoltaic Cells Based on Improved YOLOv8
Ying Zhou, Yuze Yan, Haiyong Chen, and Shenghu Pei
A YOLOv8-based defect detection algorithm, YOLOv8-EL, is proposed to address the problems of false detection and missing detection caused by data imbalance, varied defect scales, and complex background textures in photovoltaic (PV) cell defect detection. First, GauGAN is used for data augmentation to address the issue of intra-class and inter-class imbalance, improve model generalization ability, and reduce the risk of overfitting. Second, a context aggregation module is embedded between the backbone network and the feature fusion network to adaptively fuse semantic information from different levels, align local features, reduce the loss of minor defect information, and suppress irrelevant background interference. Finally, a multi-attention detection head is constructed to replace the decoupling head, introducing different attention mechanisms to refine classification and localization tasks, extract key information at the spatial and channel levels, and reduce feature confusion. Experimental results show that the proposed model achieves an average precision of 89.90% on the expanded PV cell EL dataset with a parameter count of 13.13×106, achieving both precision improvement and lightweight deployment requirements. Generalization experiments on the PASCAL VOC dataset demonstrate the improved algorithm's generalization performance. A YOLOv8-based defect detection algorithm, YOLOv8-EL, is proposed to address the problems of false detection and missing detection caused by data imbalance, varied defect scales, and complex background textures in photovoltaic (PV) cell defect detection. First, GauGAN is used for data augmentation to address the issue of intra-class and inter-class imbalance, improve model generalization ability, and reduce the risk of overfitting. Second, a context aggregation module is embedded between the backbone network and the feature fusion network to adaptively fuse semantic information from different levels, align local features, reduce the loss of minor defect information, and suppress irrelevant background interference. Finally, a multi-attention detection head is constructed to replace the decoupling head, introducing different attention mechanisms to refine classification and localization tasks, extract key information at the spatial and channel levels, and reduce feature confusion. Experimental results show that the proposed model achieves an average precision of 89.90% on the expanded PV cell EL dataset with a parameter count of 13.13×106, achieving both precision improvement and lightweight deployment requirements. Generalization experiments on the PASCAL VOC dataset demonstrate the improved algorithm's generalization performance.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812008 (2024)

Laser Radar 3D Target Detection Based on Improved PointPillars
Feng Tian, Chao Liu, Fang Liu, Wenwen Jiang, Xin Xu, and Ling Zhao
A 3D object detection method based on improved PointPillars model is proposed to address the problem of poor detection performance of small objects in current point cloud based 3D object detection algorithms. First, the pillar feature network in the PointPillars model is improved, and a new pillar encoding module is proposed. Average pooling and attention pooling are introduced into the encoding network, fully considering the local detailed geometric information of each pillar module, which improve the feature representation ability of each pillar module and further improve the detection performance of the model on small targets. Second, based on ConvNeXt, the 2D convolution downsampling module in the backbone network is improved to enable the model extract rich context semantic information and global features during feature extraction process, thus enhancing the feature extraction ability of the algorithm. The experimental results on the public dataset KITTI show that the proposed method has higher detection accuracy. Compared with the original network, the improved algorithm has an average detection accuracy improvement of 3.63 percentage points, proving the effectiveness of the method. A 3D object detection method based on improved PointPillars model is proposed to address the problem of poor detection performance of small objects in current point cloud based 3D object detection algorithms. First, the pillar feature network in the PointPillars model is improved, and a new pillar encoding module is proposed. Average pooling and attention pooling are introduced into the encoding network, fully considering the local detailed geometric information of each pillar module, which improve the feature representation ability of each pillar module and further improve the detection performance of the model on small targets. Second, based on ConvNeXt, the 2D convolution downsampling module in the backbone network is improved to enable the model extract rich context semantic information and global features during feature extraction process, thus enhancing the feature extraction ability of the algorithm. The experimental results on the public dataset KITTI show that the proposed method has higher detection accuracy. Compared with the original network, the improved algorithm has an average detection accuracy improvement of 3.63 percentage points, proving the effectiveness of the method.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812007 (2024)
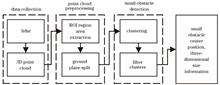
Small-Scale Rockfall Detection Method Based on Solid-State Lidar for Unstructured Transportation Roads in Open-Pit Mines
Qinghua Gu, Jiawei Li, Lu Chen, and Hejie Zhu
To address the challenges faced in the real-time detection of small-size rockfalls in open-pit mines during the transportation of ores using unmanned carts owing to suboptimal road conditions, intense lighting, and heavy dust, this study proposes a method for detecting small-size rockfalls in open-pit mines based on solid-state lidar. The proposed method employed a double-echo lidar for data acquisition, effectively reducing dust interference and extracting the driving area in front of the vehicle. Subsequently, a ground segmentation algorithm (straight-line fitting) based on fan surfaces was employed to segment the rough and unstructured terrains having slopes. Moreover, a hierarchical grid tree model known as octree was introduced to enhance the efficiency of neighborhood search. Furthermore, the two-color nearest pair method was applied to construct a graph, rapidly generating the clusters. Finally, the concept of adaptive clustering radius ε was adopted for clustering and obtaining the box models of small-size rockfalls. The experimental results demonstrate that the proposed method outperforms the k-d tree-accelerated DBSCAN algorithm, increasing the positive detection rate by 9.61 percentage points and reducing the detection time by 379.77 ms. To address the challenges faced in the real-time detection of small-size rockfalls in open-pit mines during the transportation of ores using unmanned carts owing to suboptimal road conditions, intense lighting, and heavy dust, this study proposes a method for detecting small-size rockfalls in open-pit mines based on solid-state lidar. The proposed method employed a double-echo lidar for data acquisition, effectively reducing dust interference and extracting the driving area in front of the vehicle. Subsequently, a ground segmentation algorithm (straight-line fitting) based on fan surfaces was employed to segment the rough and unstructured terrains having slopes. Moreover, a hierarchical grid tree model known as octree was introduced to enhance the efficiency of neighborhood search. Furthermore, the two-color nearest pair method was applied to construct a graph, rapidly generating the clusters. Finally, the concept of adaptive clustering radius ε was adopted for clustering and obtaining the box models of small-size rockfalls. The experimental results demonstrate that the proposed method outperforms the k-d tree-accelerated DBSCAN algorithm, increasing the positive detection rate by 9.61 percentage points and reducing the detection time by 379.77 ms.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812006 (2024)

Algorithm for Detecting Laser Soldering Point Defect Based on Improved YOLOv5s
Penghui Yan, Xubing Chen, Yili Peng, and Fadong Xie
To address the high cost of detection equipment and slow detection speed of traditional algorithms for detecting point defects in laser soldering on the production line, we propose an improved YOLOv5s algorithm that can directly detect defects on the laser soldering equipment. By introducing GhostNetV2 convolution mechanism, the backbone network is lightweight improved, the parameter quantity of the original network model reduced and the detection speed increased. Simultaneously, omni-dimensional dynamic convolution module is used to improve both the feature extraction capability and detection accuracy of the model. The experimental results show that the improved YOLOv5s model has a reduced network parameter quantity of 23.89% compared to the original model. The mean average precision of improved model reached 95.0% on the self-made laser soldering point defect dataset and validation set, reflecting a 1 percentage point improvement over the original model. The detection rate increased by 12.62 frame/s on the experimental platform compared to the original model. Finally, the proposed algorithm is deployed on the laser soldering equipment and can detect corresponding soldering defects at a running speed of 42.2 frame/s, basically meet the real-time welding defect detection needs of laser soldering. To address the high cost of detection equipment and slow detection speed of traditional algorithms for detecting point defects in laser soldering on the production line, we propose an improved YOLOv5s algorithm that can directly detect defects on the laser soldering equipment. By introducing GhostNetV2 convolution mechanism, the backbone network is lightweight improved, the parameter quantity of the original network model reduced and the detection speed increased. Simultaneously, omni-dimensional dynamic convolution module is used to improve both the feature extraction capability and detection accuracy of the model. The experimental results show that the improved YOLOv5s model has a reduced network parameter quantity of 23.89% compared to the original model. The mean average precision of improved model reached 95.0% on the self-made laser soldering point defect dataset and validation set, reflecting a 1 percentage point improvement over the original model. The detection rate increased by 12.62 frame/s on the experimental platform compared to the original model. Finally, the proposed algorithm is deployed on the laser soldering equipment and can detect corresponding soldering defects at a running speed of 42.2 frame/s, basically meet the real-time welding defect detection needs of laser soldering.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812005 (2024)
Real-Time Detection of Abnormal Behavior of Escalator Passengers Based on YOLOv5s
Yuanpeng Wang, Haibin Wan, Kai Huang, Zhaozhan Chi, Jinqi Zhang, and Zhixing Huang
To detect passengers' abnormal behavior in real time, we propose a lightweight escalator passenger' abnormal behavior real-time detection algorithm, YOLO-STE, based on YOLOv5s. First, a lightweight ShuffleNetV2 network was introduced in the backbone network to reduce the number of parameters and its computation. Second, a C3TR module based on Transformer encoding was introduced in the last layer of the backbone network to better extract rich global information and fuse features at different scales. Finally, an SE (Squeeze-and-excitation) attention mechanism was embedded in the feature fusion network of YOLOv5s to better focus on the main information and improve the model accuracy. We developed our dataset and conducted experiments. The experimental results demonstrate that compared with the original YOLOv5s, the mean Average Precision (mAP) of the improved algorithm is 1.9 percentage points higher, reaching 96.1%, and the model size is reduced by 70.8%. Moreover, the improved algorithm's forward propagation time is 39.9% shorter than that of the original YOLOv5s model when deployed and tested on the Jetson Nano hardware. Compared with the original YOLOv5s model, the improved algorithm can better achieve real-time detection of abnormal behavior of escalator passengers, which can better ensure the safety of passengers riding the escalator. To detect passengers' abnormal behavior in real time, we propose a lightweight escalator passenger' abnormal behavior real-time detection algorithm, YOLO-STE, based on YOLOv5s. First, a lightweight ShuffleNetV2 network was introduced in the backbone network to reduce the number of parameters and its computation. Second, a C3TR module based on Transformer encoding was introduced in the last layer of the backbone network to better extract rich global information and fuse features at different scales. Finally, an SE (Squeeze-and-excitation) attention mechanism was embedded in the feature fusion network of YOLOv5s to better focus on the main information and improve the model accuracy. We developed our dataset and conducted experiments. The experimental results demonstrate that compared with the original YOLOv5s, the mean Average Precision (mAP) of the improved algorithm is 1.9 percentage points higher, reaching 96.1%, and the model size is reduced by 70.8%. Moreover, the improved algorithm's forward propagation time is 39.9% shorter than that of the original YOLOv5s model when deployed and tested on the Jetson Nano hardware. Compared with the original YOLOv5s model, the improved algorithm can better achieve real-time detection of abnormal behavior of escalator passengers, which can better ensure the safety of passengers riding the escalator.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812004 (2024)
Bronze Dating Identification Method Based on Bounded Classifiers in Deep Learning
Baiqiang Li, Guangxu Pan, Tianqian Li, Dong Zhu, Lu Bai, Xiaoming Yang, Peigang Liu, and Kunqiang Wen
Identifying the age of ancient bronze vessels requires many relevant historical materials, takes a long time, and has strong subjectivity. We propose a new approach to assist archaeologists in analyzing and dating ancient bronze artifacts. The proposed method applies deep learning methods for age discrimination of ancient bronze artifacts based on image classification pre training weights. First, through multiple basic experiments, EfficientNetV2-L with good discrimination results is selected as the baseline model from four representative network models. Thereafter, EfficientNetV2-L is used to extract features from the ancient bronze ware dataset, and then, the original linear classification layer is replaced with cosin_classifier to reduce the risk caused by variance and improve the model's discrimination ability. Finally, the focal loss function is introduced to replace the original cross entropy loss function for loss calculation. Under the influence of the focusing parameter and class weighting factor, the poor model learning performance caused by a small number of samples and categories is effectively reduced. The proposed method improves the accuracy, precision, recall, F1 score, and area under the curve by 4.1 percentage points, 4.0 percentage points, 4.1 percentage points, 4.2 percentage points, and 0.9 percentage points, respectively, compared to the original EfficientNetV2-L, achieving an optimal accuracy of 91.7% on the test set. Additionally, a model prediction analysis is conducted on controversial bronze artifacts with different stages. The results indicate that deep learning technology is effective in identifying the age of ancient bronze ware datasets, providing reference analysis data and reducing the workload of archaeological experts. Identifying the age of ancient bronze vessels requires many relevant historical materials, takes a long time, and has strong subjectivity. We propose a new approach to assist archaeologists in analyzing and dating ancient bronze artifacts. The proposed method applies deep learning methods for age discrimination of ancient bronze artifacts based on image classification pre training weights. First, through multiple basic experiments, EfficientNetV2-L with good discrimination results is selected as the baseline model from four representative network models. Thereafter, EfficientNetV2-L is used to extract features from the ancient bronze ware dataset, and then, the original linear classification layer is replaced with cosin_classifier to reduce the risk caused by variance and improve the model's discrimination ability. Finally, the focal loss function is introduced to replace the original cross entropy loss function for loss calculation. Under the influence of the focusing parameter and class weighting factor, the poor model learning performance caused by a small number of samples and categories is effectively reduced. The proposed method improves the accuracy, precision, recall, F1 score, and area under the curve by 4.1 percentage points, 4.0 percentage points, 4.1 percentage points, 4.2 percentage points, and 0.9 percentage points, respectively, compared to the original EfficientNetV2-L, achieving an optimal accuracy of 91.7% on the test set. Additionally, a model prediction analysis is conducted on controversial bronze artifacts with different stages. The results indicate that deep learning technology is effective in identifying the age of ancient bronze ware datasets, providing reference analysis data and reducing the workload of archaeological experts.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812003 (2024)
Water Contact Angle Calculation Method Based on Faster RCNN
Hui Wang, Jun Wang, and Zhaoliang Cao
A water contact angle measurement method based on the improved Faster RCNN is proposed to address the issues of low accuracy and poor reproducibility caused by manual intervention in traditional water contact angle measurement processes. First, the Faster RCNN backbone network VGG16 was replaced with ResNet101, and the attention mechanism model convolutional block attention module (CBAM) was added at the end of its residual block to enhance the network's ability to extract features. Second, the feature pyramid network (FPN) was incorporated to fully extract feature information at different scales, and the Focal loss function was introduced to solve the problem of imbalanced positive and negative class samples. Finally, edge detection and corner extraction were performed on the located water droplets, and then the iterative reweighted least squares (IRLS) method was used to fit the elliptical contour to calculate the contact angle angle. The experimental results show that the improved Faster RCNN object detection algorithm improves mean average precision by 10.794% and speed by 11 frame/s over the original algorithm. The average standard deviation of contact angle angle measurements is 0.109°. A water contact angle measurement method based on the improved Faster RCNN is proposed to address the issues of low accuracy and poor reproducibility caused by manual intervention in traditional water contact angle measurement processes. First, the Faster RCNN backbone network VGG16 was replaced with ResNet101, and the attention mechanism model convolutional block attention module (CBAM) was added at the end of its residual block to enhance the network's ability to extract features. Second, the feature pyramid network (FPN) was incorporated to fully extract feature information at different scales, and the Focal loss function was introduced to solve the problem of imbalanced positive and negative class samples. Finally, edge detection and corner extraction were performed on the located water droplets, and then the iterative reweighted least squares (IRLS) method was used to fit the elliptical contour to calculate the contact angle angle. The experimental results show that the improved Faster RCNN object detection algorithm improves mean average precision by 10.794% and speed by 11 frame/s over the original algorithm. The average standard deviation of contact angle angle measurements is 0.109°.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812002 (2024)
Lightweight Pavement Crack Detection Model Based on DeepLabv3+
Xiaohua Xia, Jiangong Su, Yaoyao Wang, Yang Liu, and Mingzhen Li
Cracks are one of the main road surface diseases, and timely and effective crack detection and evaluation are crucial for road maintenance. To achieve fast and accurate semantic segmentation of road crack images, a road crack detection method based on the DeepLabv3+ model is proposed. To reduce the number of model parameters and improve inference speed, MobileNetv3 is used as the model's backbone feature extraction network, and Ghost convolution is used instead of ordinary convolution in the atrous spatial pyramid pooling module to make the model lightweight. To avoid degrading model accuracy by replacing the backbone network, the following measures are adopted. First, a strip pooling module is used in the atrous spatial pyramid pooling module to effectively capture the contextual information of crack structures while avoiding interference from irrelevant regional noise. Second, a lightweight channel attention mechanism, the effective channel attention (ECA) module, is introduced to enhance the feature expression ability, and a shallow feature fusion structure is designed to enrich the image's detailed information, optimizing the model's crack recognition effect. Finally, a mixed loss function is proposed to address the issue of low detection accuracy caused by imbalanced categories in the crack dataset, and transfer learning training is used to improve the model's generalization ability. The experimental results show that the proposed road crack detection model's parameters are only 14.53 MB, which is 93.04% less than the original model parameters, and the average frame rate reaches 47.18, meeting the requirements of real-time detection. In terms of accuracy, the intersection to union ratio and F1 value of this model's crack detection results are 57.21% and 72.76%, respectively, which are superior to classic DeepLabv3+, PSPNet, and U-Net models, as well as advanced FPBHN, ACNet, and other models. The proposed method can significantly reduce the number of model parameters while maintaining road crack detection accuracy and meeting real-time requirements, thus laying the foundation for online detection of road cracks based on semantic segmentation. Cracks are one of the main road surface diseases, and timely and effective crack detection and evaluation are crucial for road maintenance. To achieve fast and accurate semantic segmentation of road crack images, a road crack detection method based on the DeepLabv3+ model is proposed. To reduce the number of model parameters and improve inference speed, MobileNetv3 is used as the model's backbone feature extraction network, and Ghost convolution is used instead of ordinary convolution in the atrous spatial pyramid pooling module to make the model lightweight. To avoid degrading model accuracy by replacing the backbone network, the following measures are adopted. First, a strip pooling module is used in the atrous spatial pyramid pooling module to effectively capture the contextual information of crack structures while avoiding interference from irrelevant regional noise. Second, a lightweight channel attention mechanism, the effective channel attention (ECA) module, is introduced to enhance the feature expression ability, and a shallow feature fusion structure is designed to enrich the image's detailed information, optimizing the model's crack recognition effect. Finally, a mixed loss function is proposed to address the issue of low detection accuracy caused by imbalanced categories in the crack dataset, and transfer learning training is used to improve the model's generalization ability. The experimental results show that the proposed road crack detection model's parameters are only 14.53 MB, which is 93.04% less than the original model parameters, and the average frame rate reaches 47.18, meeting the requirements of real-time detection. In terms of accuracy, the intersection to union ratio and F1 value of this model's crack detection results are 57.21% and 72.76%, respectively, which are superior to classic DeepLabv3+, PSPNet, and U-Net models, as well as advanced FPBHN, ACNet, and other models. The proposed method can significantly reduce the number of model parameters while maintaining road crack detection accuracy and meeting real-time requirements, thus laying the foundation for online detection of road cracks based on semantic segmentation.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0812001 (2024)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20